Token Maturation: What If LLMs Could Think Before They Speak?
Autoregressive generation via continuous token dynamics — delaying discretization for more stable output
I’m excited to share my latest work at IBM Research: “Token Maturation: Autoregressive Language Generation via Continuous Token Dynamics.”
What if we let language models think before they speak? Not by adding more layers, but by changing when discretization happens. Standard autoregressive LLMs commit to a discrete token at every step — prediction and commitment are fused into a single operation. This forces uncertainty to collapse immediately, leading to degenerate repetition under greedy decoding and dependence on sampling heuristics.
Token Maturation decouples prediction from commitment. It opens a new design space for generative models where prediction and commitment are separated, enabling more stable and controllable generation — all without sampling tricks, repetition penalties, or temperature tuning.
The Core Insight
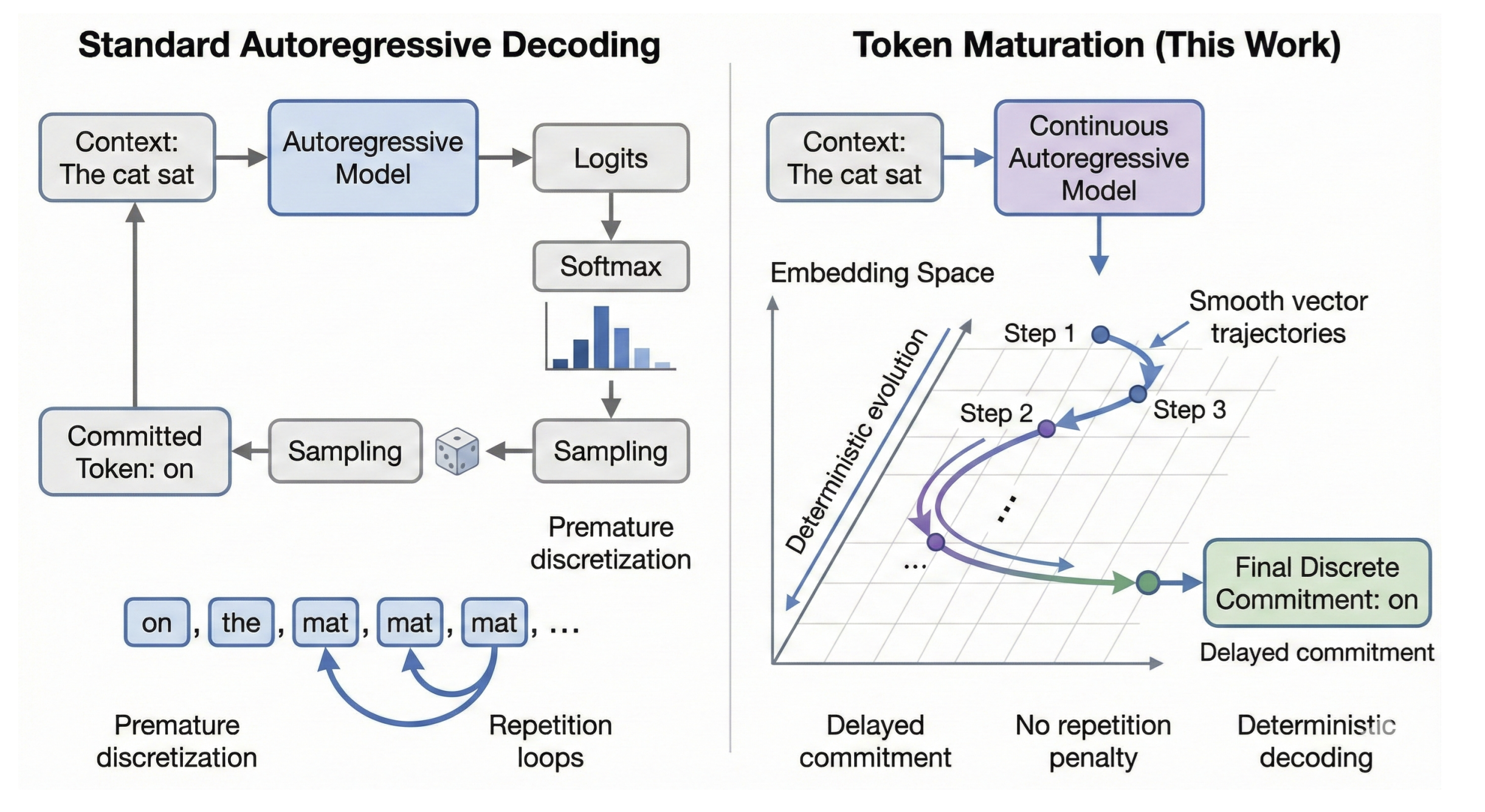
Standard autoregressive LLMs commit to a discrete token at every step — prediction and commitment are fused into a single operation. This forces uncertainty to collapse immediately, leading to degenerate repetition under greedy decoding and dependence on sampling heuristics.
Token Maturation decouples prediction from commitment. The generation state is a sequence of continuous vectors. New tokens emerge through iterative refinement in embedding space, and discrete commitment happens only when vectors geometrically stabilize — not when probability concentrates.
Key Concepts
Continuous State — The entire sequence, including already-generated tokens, lives in continuous embedding space. No discrete indices until final projection.
Delayed Commitment (The Liquid Tail) — A “liquid tail” of K vectors is iteratively refined. Tokens are committed only when they reach the front of the buffer.
Geometric Stability — Commitment occurs via nearest-neighbor projection when vectors stabilize — even if the induced token distribution remains high-entropy.
How It Works
The method follows three steps:
Step 1: Continuous Representation. Tokens are represented as vectors z_t in R^d in embedding space. The model predicts continuous vectors, not logits over vocabulary.
Step 2: Iterative Refinement. The liquid tail is updated via contraction: the refined vector moves toward the model’s prediction, with a learning rate that depends on position in the tail. Vectors closer to the front of the tail receive stronger updates.
Step 3: Projection & Commit. When a vector reaches the front of the tail, it is committed via nearest-neighbor projection to the closest token embedding.
The training loss combines MSE (to ensure geometric convergence) with InfoNCE (to prevent collapse toward the mean and anchor predictions to discrete token identities).
Generation Demo
Tail tokens appear as incoherent noise. The model explores freely without context steering.
Tail tokens form interpretable lookahead -- thematic concepts visible before commitment.
Classifier-Free Guidance pulls tail vectors toward the manifold of coherent text, making the liquid tail a window into the model’s implicit forward planning.
Classifier-Free Guidance Reveals Interpretable Lookahead
With the prompt “The meaning of life is”:
With CFG (s=2.0): The committed text reads “Love yourself unconditionally regardless of whether or not you deserve it.” ~John Wesley. The liquid tail shows thematically relevant concepts: toward, humility, begins, faith, grows, humble, strive — coherent lookahead into future meaning.
Without CFG (s=1.0): The committed text reads “To live happily ever after…and always.” ~ John Paul II. The liquid tail shows incoherent noise: repetition of This, This, This, raw bytes, and random tokens.
CFG transforms the liquid tail from noise into a semantic preview of where the generation is heading.
Emergent Template Attractors
Token Maturation often converges to a stable structural template while varying surface-level entities. For the prompt “The meaning of life is…”:
- “eternal happiness,” says Dr. James Wilson, director of Psychiatry…
- “eternal peace,” says Dr. R. Ehrlichman, director of Stanford Med…
- “to know thyself,” says Dr. David Hahn, director of Neuroscience…
The structural pattern [Quote -> Attribution -> Role] remains stable across runs, while specific names, quotes, and institutions vary freely. The model discovers and locks onto an abstract narrative template while allowing concrete details to remain fluid.
Results
Repetition Metrics
Token Maturation eliminates degenerate repetition under pure greedy decoding — no penalties, no temperature, no sampling.
| Metric | Token Maturation (Ours) | Standard Greedy | Greedy + Penalty |
|---|---|---|---|
| Dist-1 | 0.974 | 0.228 | 0.936 |
| Dist-2 | 1.000 | 0.301 | 0.999 |
| Rep-2 | 0.000 | 0.699 | 0.001 |
| Rep-3 | 0.000 | 0.665 | 0.000 |
| Loop % | 0% | 90% | 0% |
All models use the same GPT-2 Medium backbone. Loop% = fraction of samples containing any repeated trigram.
Coherent Generation Without Entropy Collapse
A key finding: discrete commitment need not coincide with probability concentration. The entropy of the induced token distribution often remains high (~3.9 nats) throughout maturation, yet generation stays coherent.
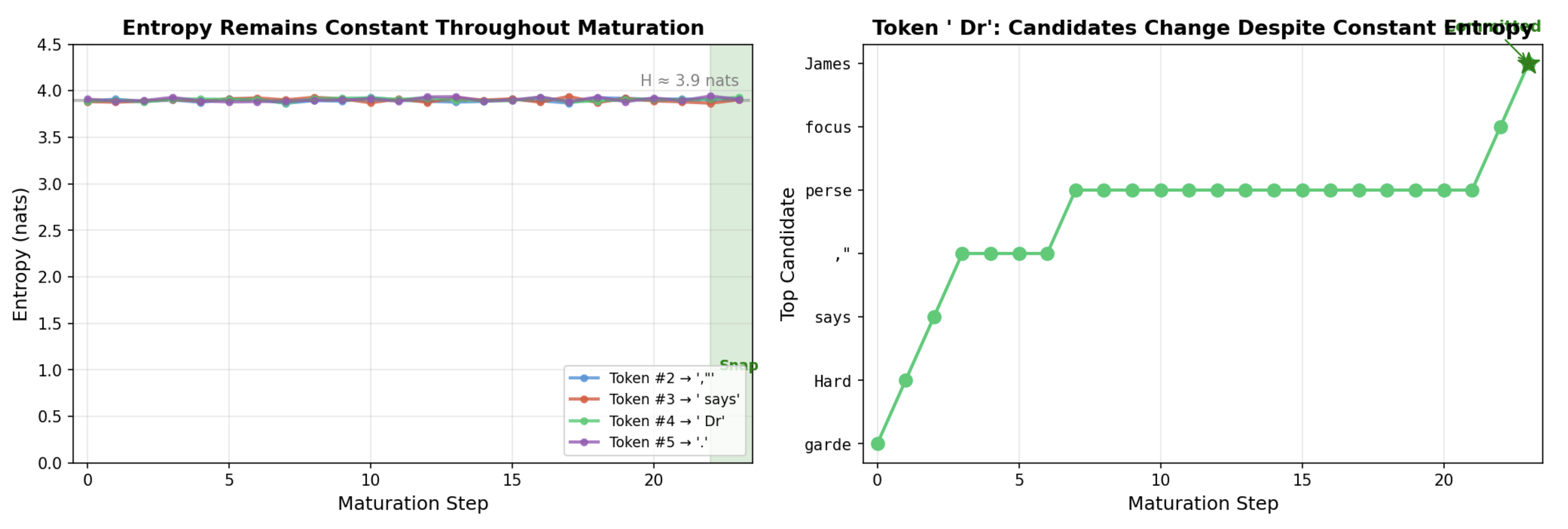
Left: Entropy remains constant (~3.9 nats) throughout maturation — uncertainty does not collapse. Right: The top-1 candidate for the “Dr” token flickers between options despite stable entropy, showing geometric convergence without probabilistic certainty.
This is a surprising and important result: the model converges to coherent output through geometric stability in embedding space, not through the traditional route of collapsing probability mass onto a single token.
Citation
@article{tokenmaturation2025,
title={Token Maturation: Autoregressive Language Generation
via Continuous Token Dynamics},
author={Anonymous},
journal={arXiv preprint arXiv:2601.04854},
year={2025}
}